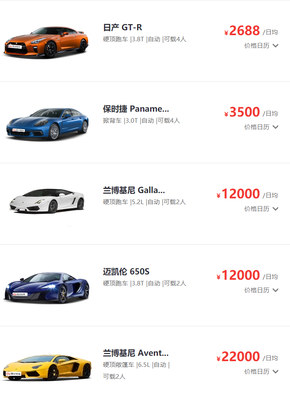
北京安速達汽車租賃有限責任公司產品展示

北京安速達汽車租賃有限責任公司是一家專注于提供高品質汽車租賃服務的專業公司,致力于滿足個人、企業及機構的多元化出行需求。憑借豐富的車型選擇、靈活的租車方案和貼心的客戶服務,安速達已成為北京地區汽車租賃行業的領先品牌。以下為公司的核心產品與服務介紹:
一、 車型多樣,滿足不同需求
公司提供從經濟型到豪華型的全方位車型選擇,覆蓋轎車、SUV、MPV及商務車等多種類型。經濟車型如豐田卡羅拉、大眾朗逸,適合日常通勤和短途旅行;中高端車型如奧迪A6、寶馬5系,滿足商務接待和品質出行需求;SUV和MPV車型如本田CR-V、別克GL8,則為家庭出游或團隊活動提供寬敞空間。所有車輛均定期維護,確保安全可靠。
二、 租車方案靈活便捷
安速達提供短期、長期及定制化租賃方案。短期租賃適合臨時用車、旅游或商務差旅,按日或周計費,手續簡便;長期租賃面向企業客戶,可享受優惠月租或年租價格,并包含保險和維護服務。公司還支持線上預訂、上門送車和異地還車,提升客戶體驗。
三、 附加服務與保障
為保障客戶權益,公司提供全面的保險選項,包括車輛損失險和第三方責任險。提供24小時道路救援服務,確保行車無憂。客戶還可選擇GPS導航、兒童座椅等附加設備,滿足個性化需求。企業客戶可享受專屬客戶經理服務,簡化租賃流程。
四、 客戶服務與承諾
安速達以客戶為中心,提供專業咨詢和透明定價,無隱藏費用。公司秉承“安全、速度、抵達”的理念,通過數字化平臺優化服務效率,確保每一段旅程都舒適高效。無論是個人休閑還是企業用車,安速達都致力于成為您信賴的出行伙伴。
歡迎訪問公司官網或聯系客服熱線,了解更多產品詳情并預訂服務。北京安速達汽車租賃有限責任公司,助您輕松出行,暢享駕駛樂趣!
如若轉載,請注明出處:http://www.hdnzp.cn/product/48.html
更新時間:2026-06-19 10:41:44